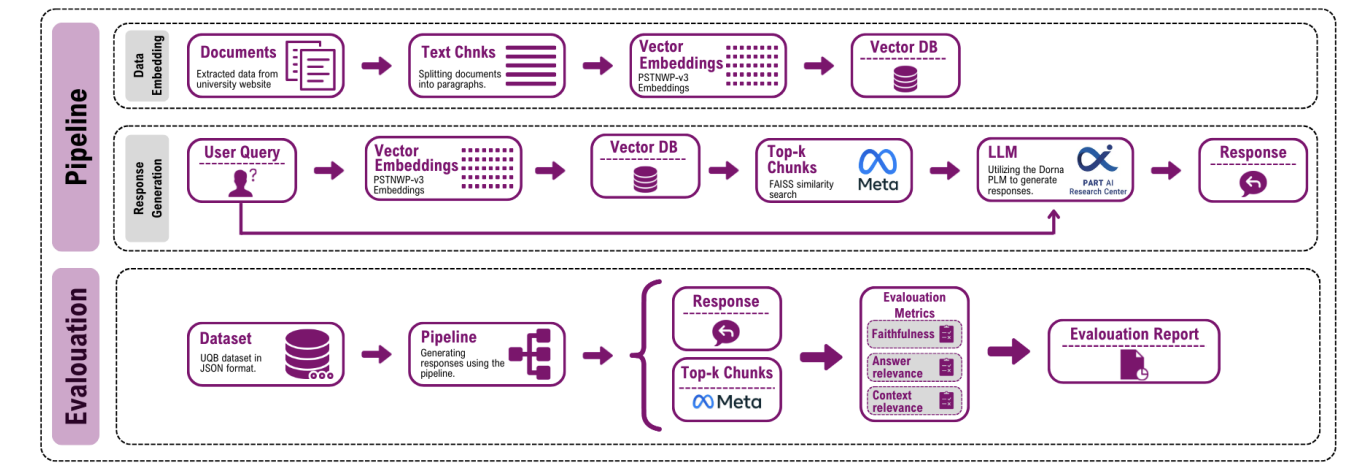
In this project we develop a two‑stage retrieval‑augmented generation pipeline to answer questions about university resources using locally scraped documents. Queries are first categorised to determine the most relevant subset of documents; a Persian large language model then generates answers using a carefully engineered prompt. This approach combines the power of large language models with explicit retrieval, ensuring that answers remain faithful to the underlying knowledge base.
To evaluate our system, we introduce UniversityQuestionBench (UQB), a benchmark derived from frequently asked questions by students across disciplines. We measure performance using faithfulness, answer relevance and context relevance metrics. Experiments demonstrate that incorporating retrieval significantly improves the precision and contextual relevance of generated answers compared with baselines that rely solely on generative models. Our work highlights the value of domain‑specific RAG systems for institutional knowledge retrieval.